
Week 4 + Week 5 (ASR - German)
Link to Repository of Code
Describe my work briefly
I am happy to update on my Week 4 and Week 5 progress. I am progressing well with the project as per the proposal. This would be the evaluation period. I am totally excited.
I spent this period working on Language and Phoneme Modeling.
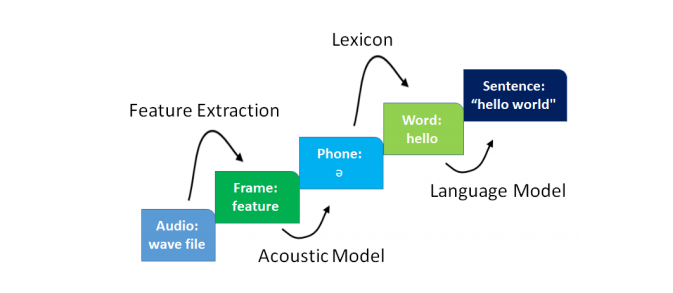
Language Modeling
A language model (LM) is a probability distribution over sequences of words, P(W), which is decomposed as:
P(W) = P(w1, w2, ..., wn) = P(w1)P(w2|w1)· · · P(wn|w1, . . . , wn−1)
And each of these probabilities could be estimated using maximum likelihood methods by checking counts of word sequences txt c(w1, . . . , wn) in the training corpus.
P(wn|w1, . . . , wn−1)=c(w1, w2, . . . , wn)/c(w1, w2, ..., wn−1)
Due to the sparsity of training data, typical language models for ASR make a k-order Markov assumption, i.e.
P(wn|w1, . . . , wn−1) = P(wn|wn−k, . . . , wn−1)
In real ASR applications, k = 2 and k = 3 are the most common settings, and corresponding LMs are called “bigram model” and “trigram model” respectively.
For language modeling, I used “German speech data corpus.” The corpus is of approximately 8 million German sentences. MaryTTS is used to normalize the text to a form that is close to how a reader would speak the sentence, e.g., any numbers and dates are converted into a canonical text form, and any punctuation is discarded. The corpus is appropriately filtered so that sentences from the development and test speech corpus are not included in the LM.
Phoneme Dictionary
A lexicon, also called a dictionary, is a map from written words to their pronunciations in phones. This component helps to bridge the gap between words in written form and their acoustics. The use of a lexicon makes it possible to recognize words that do not appear in the training set. Even for words that do not appear in the lexicon, we can use another technique called “grapheme to phoneme” (G2P) to predict pronunciation for them using their written form.
A phoneme is a speech segment that possesses distinct physical or perceptual properties and serves as the basic unit of phonetic speech analysis. For a commonly spoken language, several phones may range from 40 to a few hundred. Phones are generally either vowels or consonants, and they may last 5 to 15 frames (50 to 150ms). During testing, the lexicon is used to restrict the search path so that phone strings are valid, and to convert phone strings to words.
Extensive German phoneme dictionary has strict licensing issues. The researchers at the University of Hamburg, Germany have written some scripts to combine several small phoneme dictionaries. The final dictionary covers 44.8k unique German words with 70k total entries, with alternate pronunciations for some of the more common words. The pronunciation dictionary is of a reasonable size for large-vocabulary speech recognition.
I will keep you posted about my progress!
Leave a Comment