
Week 1 (ASR - German)
Link to Repository of Code
Describe my work briefly
I am excited to start my 13 weeks journey with Distributed Little Red Hen Labs. Also, I am incredibly thankful to all my mentors for allowing me to start early for the project, so I can later take a break for a few days during my exams.
Kaldi
Today, I complete my Week-1. The essential task during this week was to engage deeper in Kaldi. Kaldi is a toolkit for Speech Recognition written in C++ and licensed under the Apache License v2.0. The documentation is not straight-forward, but I tried to summarize according to my understanding and point out resources that helped on my way. An Automatic Speech Recognition pipeline has four significant steps:
- Pre-Processing
- Feature Extraction
- Acoustic Model
- Language Model
The following is depicted in the image below:
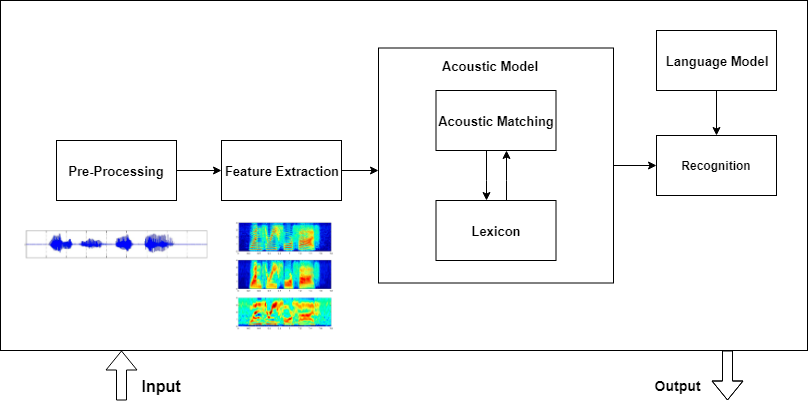
Additionally, Kaldi acoustic modeling also supports conventional models (i.e., diagonal Gaussian Mixture Models (GMMs)) and Subspace Gaussian Mixture Models (SGMMs) and thus utilizes Phonetic knowledge along with Acoustic Model.
- Phoneme Model
The following lectures by Dan Povey’s, Kaldi’s developer, helped me to build my knowledge.
-
Lecture 1 (Overview of the course; getting started with Kaldi; feature generation)
-
Lecture 2 (HMMs; monophone training)
-
Lecture 3 (phonetic-context-dependent model training)
-
Lecture 4 (basic decoding)
Moreover, an important part of the project is collecting and understanding the requisite German Speech dataset. The datasets have different structure and formats. We planned to use the following open-source corpus:
Next two week would be crucial. I would be working on data pre-processing and computing Feature Extraction of the speech data as standard 13-dimensional Mel-Frequency Cepstral Coefficients (MFCC) features.
I will keep you posted about my progress!
Leave a Comment